챗봇 MeU를 만드는 자연어 처리 모델
1. 딥러닝을 이용한 자연어 처리 모델은 무엇이 있을까?
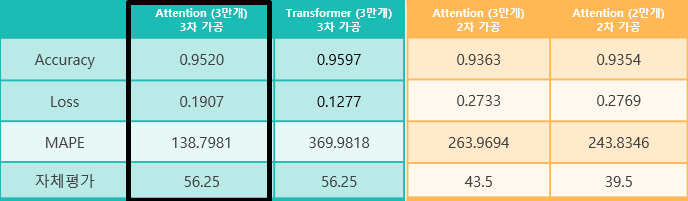
저희는 챗봇 MeU을 구현하기 위해 자연어 처리 모델인 SEQ2SEQ, Attention, Transformer, Bert를 학습시켜 보았고, 평가를 통해 하나의
모델을 선정하였습니다.
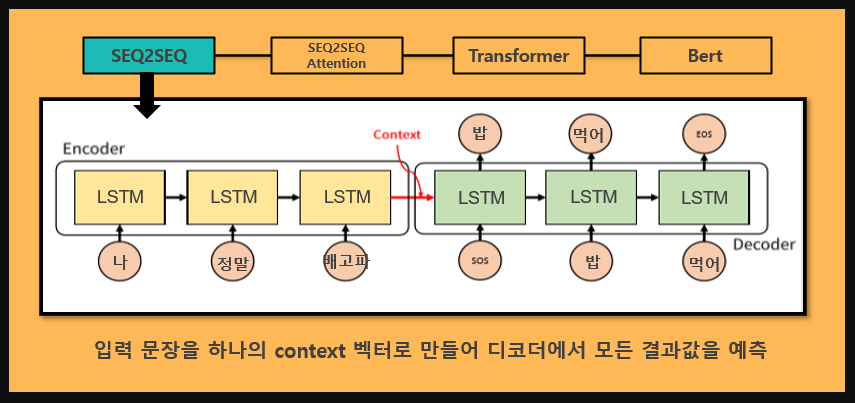
SEQ2SEQ모델은 순환신경망으로 이루어진 인코더와 디코더로 구성되어 있습니다.
인코더는 입력문장의 모든 단어를 순차적으로 입력받아 하나의 벡터로 만들고, 디코더는 이 벡터를 받아 답변을 예측합니다.
이러한 문장의 정보를 가지는 이 벡터를 context vector라고 합니다.
SEQ2SEQ는 하나의 고정된 크기의 벡터에 입력문장의 모든 정보를 압축하므로 정보의 손실이 발생한다는 단점이 있습니다.
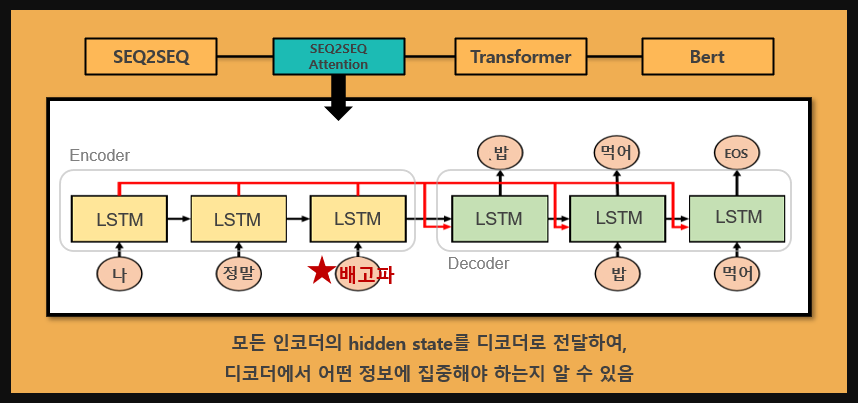
저희는 SEQ2SEQ의 문제를 해결하기 위한 방법으로 Attention 기법을 추가하였습니다.
Attention 모델은 context 벡터 뿐만 아니라 각각의 LSTM의 output 벡터를 디코더로 함께 전달합니다.
디코더는 각각의 output 벡터를 이용하여 현재 자신과 비교하여 주목해야할 입력 단어가 무엇인지 알아내고 반영할 수 있습니다.
Attention모델은 SEQ2SEQ보다 정확도를 높일 수 있지만, 여전히 순환신경망으로 인한 학습속도가 느리다는 단점이 존재합니다.
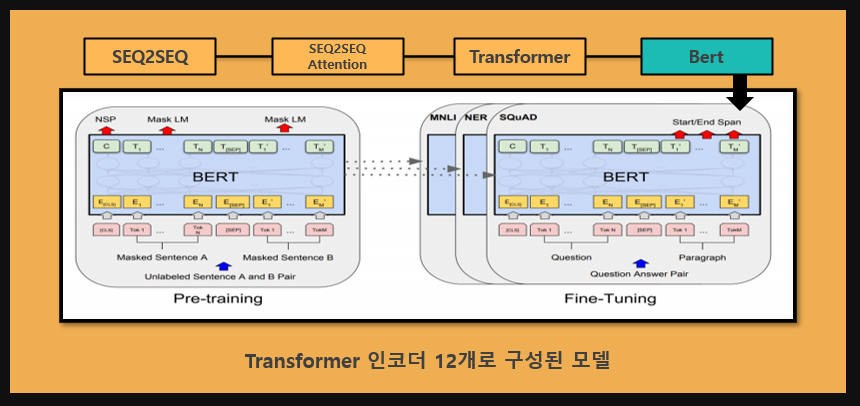
Transformer는 구글에서 발표한 논문인 'Attention is all you need(2017)'에서 제안된 모델로, 순환신경망을 없애 학습속도가 매우
빠릅니다.
인코더 디코더는 attention만으로 이루어져 있으며, 입력단어의 순서를 반영하기 위해 positional encoding을 사용합니다.
우리는 Transformer를 활용한 Bert모델 또한 구현해 보았습니다. 미리 학습된 구글 Multilingual Bert 모델을 fine-tunning하여
정보처리봇을 구현하는데 사용하였습니다.
2. 모델 평가 방법
모델의 데이터는 AI hub와 github를 통해 수집하였으며, 질문-답 형식으로 되어있는 3만개를 선택하였습니다.
저희는 성능이 가장 좋은 모델을 선택하기 위해 Transformer와 Attention 모델에 데이터의 종류, 형태소 분석기, 단어 임베딩 방법을 바꿔가며 13개의
모델을 학습시켰습니다.
모델 평가는 정답이 정해져 있지 않는 챗봇의 특성을 고려하여, 모든 팀원이 테스트셋의 예측값에 점수를 매겨 자체평가를 진행하였습니다.

또한, MAPE 오차률을 절대 평가 지표로 사용하였습니다.
그 결과 자체평가가 가장 높고 MAPE가 가장 낮은 3차가공 데이터를 활용한 Attention모델을 선정하였습니다.
3. 모델 동작 살펴보기
이 절에서는 저희가 선정한 모델이 동작하는 모습을 설명하겠습니다.
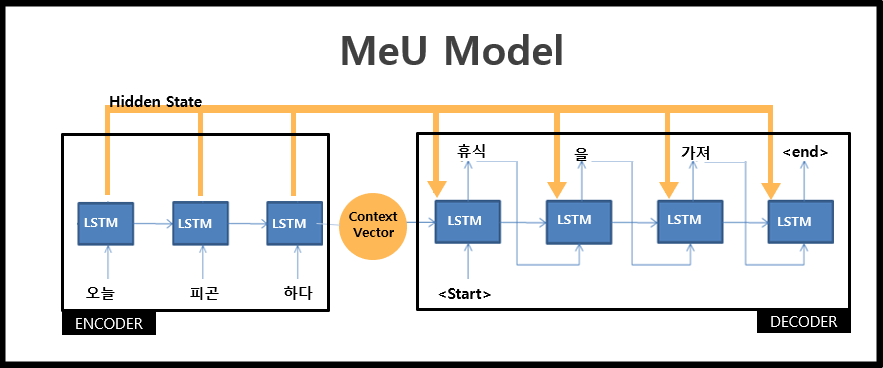
만약 그림과 같이 '오늘 피곤하다'라는 문장이 입력되면 Mecab 형태소 분석기에 의해 '오늘','피곤','하다'로 쪼개어 지게 됩니다.
이러한 각각의 형태소는 차례대로 LSTM에 들어가 context벡터와 hidden state를 출력하고, 이 값은 모두 디코더로 전달됩니다.
디코더는 이 값을 토대로 첫번째 단어인 '휴식'을 예측하는데, 여기서 중요한 것은 예측값인 '휴식'이 다시 디코더의 입력값으로 들어간다는 것입니다.
그러면 디코더는 '휴식'을 입력받아 '휴식' 다음 단어인 '을'을 예측하게 됩니다. '을'은 다시 디코더의 입력값으로 들어가고, 이 과정은 디코더가
'<end>'태그를 출력할 때까지 반복합니다.
앞서 Attention 모델은 context 벡터뿐만 아니라 hidden state를 전달함으로서 예측시에 어떤 단어 값에 집중해야 하는지 알 수 있게 된다고
언급하였습니다.
그러면 디코더에서 이 정보들을 가지고 어떻게 출력값을 예측하는지 알아보도록 하겠습니다.
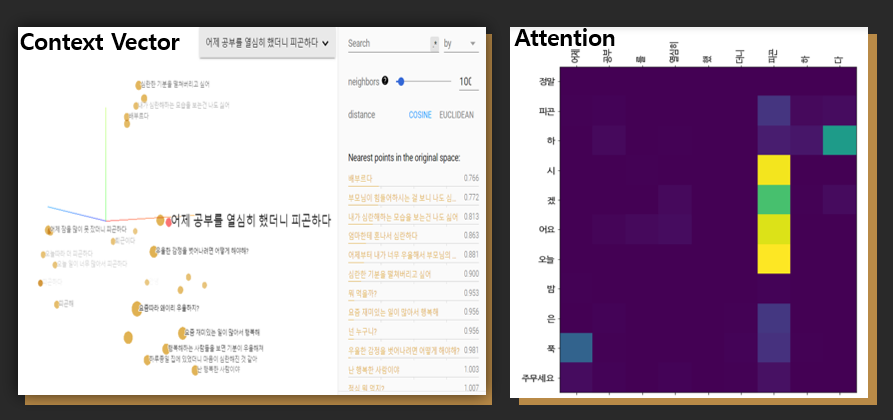
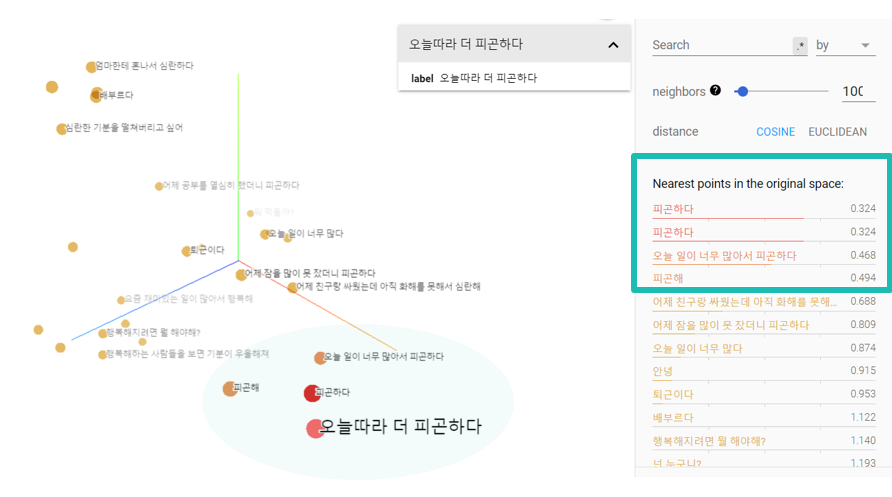
구글의 embedding projector 사이트는 다차원 벡터를 3차원으로 시각화하여 보여주는 기능을 제공합니다.
해당 그래프는 저희 인코더 모델에 30개의 문장을 넣어 만든 context벡터를 3차원으로 시각화한 것입니다.
'피곤하다', '오늘따라 더 피곤하다'같은 피곤을 키워드로 한 문장들이 비슷한 위치에 놓여있는 것을 보실 수 있습니다.
이렇게 context 벡터의 값이 유사하다는 의미는 이 문장들이 디코더에서 동일한 답변을 얻을 가능성이 크다는 것을 의미합니다.
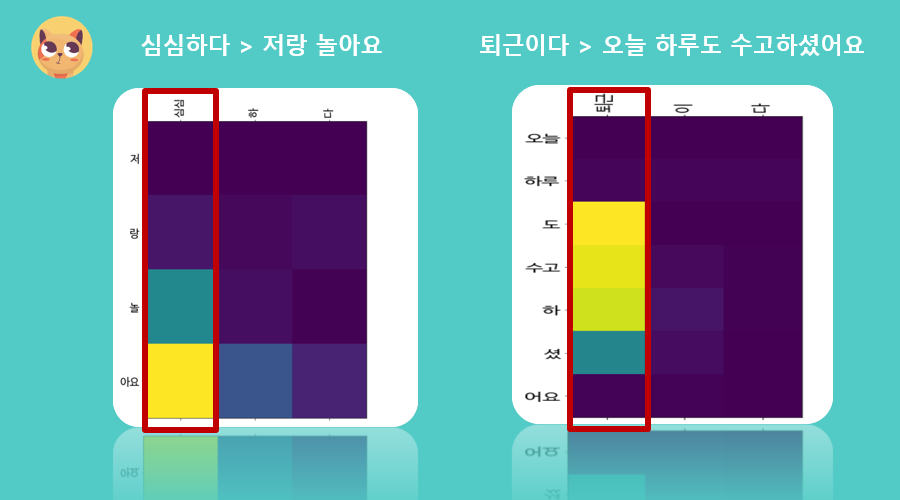
이번에는 Attention값에 대해 살펴보도록 하겠습니다.
해당 그래프는 두 문장에 대한 Attention가중치값을 시각화한 것으로, 가중치가 클수록 밝은 색상으로 표현됩니다. ‘심심하다’와 ‘퇴근하다’를 보시면 ‘하다’와
‘이다’가 아닌 핵심키워드인 ‘심심’과 ‘퇴근’에 집중된 것을 보실 수 있습니다.
디코더는 이 Attention값을 참고하여 대답을 예측합니다.
Attention 값의 활용을 보기 위해서 예시 하나를 보도록 하겠습니다.
'어제 공부했더니 피곤하다'의 context 벡터는 왼쪽 그림에서 볼 수 있듯이 '배고파'와 유사성이 가장 높으며, '피곤'을 키워드로 한 문장은 순위권에 보이지
않습니다.
만약 이러한 context 벡터만을 이용하여 출력값을 예측했다면 엉뚱한 대답이 나왔을 것입니다.
하지만 오른쪽의 Attention을 시각화한 그래프를 보시면 '피곤'에 집중하고 있는 모습을 보실 수 있습니다.
이렇게 어텐션값을 통해 디코더는 올바른 문장을 예측할 수 있었습니다.